9.1. Introduction
사람은 학습 데이터뿐만 아니라 환경과의 상호작용으로부터도 배운다. 시스템이 복잡한 환경과 상호작용해 보상이 주어지는 결과를 배우는 보상 기반 시도-오차 과정은 기계 학습에서는 강화 학습이라 불린다. 이는 간단한 비디오 게임 플레이, 알파고, 자율주행 차, 자가 학습 로봇 등에서 성과를 냈다. 강화 학습은 평가하기는 쉽지만 특정하기는 어려운 작업들에 걸맞다. 강화 학습에서 가장 간단한 문제는 여러 팔 도적 문제로, 이는 도박사가 슬롯 머신 중 하나를 골라 이득을 최대화하는 문제이다.
9.2. Stateless Algorithms: Multi-Armed Bandits
여러 팔 도적문제에서는 다른 슬롯 머신을 실험해 보는 것과 최적의 슬롯 머신을 이용하는 것간 트레이드오프가 존재한다. 이 트레이드오프를 최적화하는 데는 여러 전략이 있다.
9.2.1. Naive Algorithm
이 접근법에서는 도박사가 각 기계를 유한 번 시도하고 가장 높은 이득을 주는 기계를 영원히 사용한다. 이는 비현실적인 전략이다.
9.2.2. ε-Greedy Algorithm
이 접근법에서는 전체 횟수의 ε번만큼 탐색을 한 뒤 거기서 찾은 최선의 기계를 1 – ε번만큼 이용한다. 주된 접근법은 처음에는 높은 ε를 쓰다가 차츰 낮추는 것이다.
9.2.3. Upper Bounding Methods
ε-탐욕적 방법도 새 기계를 배우는 방법으로는 비효율적이다. 그래서 다른 접근법은 가장 높은 통계적 상한을 이득으로 갖는 기계를 사용한다. 이 경우 시도는 탐색과 이용으로 나뉘지 않는다.
9.3. The Basic Framework of Reinforcement Learning
이전의 도적 알고리즘은 상태가 없는데 이것은 일반적이지 않다. 일반적으로는 각 동작의 보상을 시스템 상태와 연관지어야 한다. 강화 학습에서는 동작을 사용해 환경과 상호작용하는 에이전트를 갖는다. 강화 학습의 주목적 중 하나는 서로 다른 상태에서의 동작의 내재적 가치를 타이밍과 보상의 추계성과 상관없이 특정하는 것이다. 학습 과정은 에이전트가 다른 상태에서의 동작의 내재적 가치에 기반해 동작을 선택하도록 돕는다. 한 상태에서 다른 상태로 전이하는 규칙과 전체 상태, 동작의 집합은 마르코프 결정 과정으로 불린다. 유한 마르코프 결정 과정은 유한 번에 끝나며 이를 에피소드라 한다. 무한 마르코프 결정 과정은 비에피소드적이라 한다.
Examples
예제론 다음 등이 있다. 틱-택-토, 체스, 바둑 등의 게임. 로봇 보행, 자율 주행 차.
9.3.1. Challenges of Reinforcement Learning
강화 학습은 지도 학습보다 어려운데 다음의 이유 등이 있다. 보상을 받았을 때 각 동작이 얼마나 기여하는지 알기 어렵다. 강화 학습 자체의 상태가 매우 많을 수 있다. 동작의 선택이 미래 선택에 대해 데이터에 영향을 미친다. 시뮬레이션과 게임 중심 환경에 비해 실 상황에서는 충분한 데이터를 모으기 어렵다.
9.3.2. Simple Reinforcement Learning for Tic-Tac-Toe
상태 없는 ε-탐욕적 알고리즘을 일반화해 틱-택-토를 학습할 수 있다. 자가 학습 시에는 테이블은 동작을 한 참가자의 관점에서 값을 업데이트한다.
9.3.3. Role of Deep Learning and a Straw-Man Algorithm
위의 전략의 목적은 어떤 수가 장기적으로 갖는 효과를 예측하기 위한 것이다. 이 접근법의 문제점은 일반적인 강화 학습에서 상태의 수가 너무 많다는 것이다. 이를 위해 심층 학습 모델은 함수 근사자의 역할을 해서 각 수의 값을 입력 상태에 대한 함수로 근사한다. ε-탐욕적 알고리즘 등은 체스에는 별로 그리 좋지는 않다. 이를 몬테 카를로 트리 탐색으로 일반화한 알파 제로는 체스에서 매우 좋은 성과를 냈다. 실 생활에서 상태는 감각적 입력으로 표현되고 심층 학습자는 이를 이용해 특정한 동작의 가치를 계산한다.
9.4. Bootstrapping for Value Function Learning
틱-택-토에 대한 ε-탐욕적 알고리즘의 일반화는 비에피소드적 세팅에는 통하지 않는다. 이 때는 붓스트래핑을 통한 온라인 업데이트를 해야 한다. 마르코프 결정 과정에서는 지수 항 계수를 결정하는 것이 중요하다. 상태-동작 쌍의 Q-함수나 Q-값은 
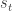
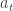
9.4.1. Deep Learning Models as Function Approximation
신경망은 상태의 특성 표현을 입력받아 각 동작에 대한 
The Q-Learning Algorithm
신경망의 가중치는 훈련을 통해 학습된다. 이 때 미래에 대한 부분적 지식만 사용해서 Q-값에 대한 개선된 추정을 할 수 있다면 손실 함수를 세팅하기 위해 Q-값을 직접 관찰할 필요는 없다. 과정이 


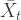
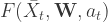

9.4.2. Example: Neural Network for Atari Setting
아타리 세팅에서는 스크린을 입력받는 컨볼루션 신경망을 이용한다. 모든 은닉층은 ReLU 활성 함수를 쓰고 출력은 실변수 Q-값을 예측하기 위해 선형 활성 함수를 쓴다.
9.4.3. On-Policy Versus Off-Policy Methods: SARSA
Q-학습 방법은 시간차 학습에 속한다. 이는 무정책 강화 학습 방법인데, 업데이트를 할 때와 동작을 실행할 때 다른 정책을 택하는 것이 업데이트의 목적인 최적해를 찾는 능력을 악화시키지 할 수 있기 때문이다. 유정책 방법에서는 동작이 업데이트와 일관적이므로 업데이트는 정책 최적화 대신 정책 평가로 보일 수 있다. 이를 이해하기 위해서는 SARSA(상태-동작-보상-상태-동작) 알고리즘을 이해해야 하는데 여기서는 다음 단계의 최적 보상이 업데이트를 계산하는 데 쓰이지 않는다. 대신 ε-탐욕적 방법에서 선택된 동작을 통해 업데이트를 수행한다. 이는 학습이 예측과 별개적으로 이뤄질 수 없는 상황에서 유용하다.
Learning Without Function Approximators
상태 공간이 매우 작을 때는 함수 근사자를 쓰지 않고 Q-값을 배울 수 있다. SARSA도 똑같이 할 수 있다.
9.4.4. Modeling States Versus State-Action Pairs
이전 문제의 변형은 상태-동작 쌍 대신 특정 상태를 배우는 것이다. 즉 상태의 가치를 
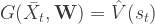



9.5. Policy Gradient Methods
Q-학습 같은 값 기반 방법은 신경망으로 동작의 가치를 예측하고 이를 일반적 정책과 연결시킨다. 반면, 정책 경사법은 전체 보상을 최대화시키는 목표 하에 각 단계의 각 동작의 확률을 추정한다. 정책을 추정하는 신경망은 정책 망으로 불리며 입력은 시스템의 현 상태이며 출력은 여러 동작과 연관된 확률값들이다. 종종 몬테 카를로 정책 롤아웃이 사용되어야 한다. 자주 쓰이는 정책 경사법은 유한 차분법, 가능도 비율법, 자연적 정책 경사법 등이 있다.
9.5.1. Finite Difference Methods
유한 차분법은 추계적 문제를 경사에 대한 추정을 하는 실측적 시뮬레이션으로 우회한다. 이 때 보상의 변화를 추정하기 위해서는 계산하는 수의 수를 충분히 늘려야 한다.
9.5.2. Likelihood Ratio Methods
가능도 비율 방법에서는 로그 확률 트릭을 써서 기대값의 경사를 계산하기 쉽게 변환시킨다. 이는 신경망 매개변수 추정으로 확장하기 쉽다. 복수의 롤아웃을 사용한다면 복수의 학습 예제에서 계산된 경사들이 각각 업데이트된다. 이는 소프트맥스와 크로스 엔트로피 손실 함수와는 Q-값을 업데이트한다는 점에서 다르다. 기준점을 일정하게 잡는 것은 분산을 감소시키는데, 상태 특징적 옵션은 동작 a를 샘플링하기 바로 직전의 상태의 가치를 뜻한다. 간단한 예제로 이를 확인해 볼 수 있다. 이는 시간차 효과를 더 크게 반영하는 효과가 있다.
9.5.3. Combining Supervised Learning with Policy Gradients
강화 학습을 적용하기 전 지도학습은 정책 망의 가중치를 초기화하는 데 유용하다.
9.5.4. Actor-Critic Methods
Q-학습과 TD(λ) 방법들은 최적화된 가치 함수와 동작한다. 정책 경사 방법은 가치 함수를 쓰지 않고 정책 동작으로부터 확률을 직접 학습한다. 이는 중간 동작의 이득을 평가해야 하며 이는 몬테 카를로 시뮬레이션에 기반해야 하는데 이는 연산량이 많다. 하지만 가치 함수를 쓰면서도 중간 동작의 이득을 학습할 수 있다. 이 경우 정책 망의 현 매개변수를 이용해 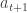
9.5.5. Continuous Action Space
이산동작공간뿐만 아니라 연속동작공간도 쓸 수 있는데, 로봇 동작 같은 경우가 그렇다. 이는 매개변수가 연속분포에서 출력을 하게 함으로써 해결한다.
9.5.6. Advantages and Disadvantages of Policy Gradients
정책망 방법은 상태와 동작의 연속된 열을 가진 용례에 가장 자연스러운 선택이다. 이는 계산적으로 가능하고 좋은 수렴 성능을 가진다. 하지만, 국소적 해에 갇힐 수 있다. 정책 망 방법은 추계적 정책을 학습할 수 있다는 장점을 갖는다.
9.6. Monte Carlo Tree Search
몬테 카를로 트리 탐색은 학습된 정책과 가치의 능력을 선제 기반 탐색으로 결합해 개선하는 것이다. 이는 AlphaGo에서 주로 사용되었다. 각 상태에서 상한이 가장 큰 동작이 선택되며 이 접근은 최적의 동작이 도달하는 노드가 존재하지 않을 때까지 계속된다.
Use in Bootstrapping
몬테 카를로 트리 탐색은 학습 시점이 아니라 추론 시점에 사용되었다. 하지만, 몬테 카를로 트리 탐색은 상태-정책 상의 값에 대한 개선된 추정을 제공하므로 붓스트래핑에도 쓸 수 있다. 알파고 제로는 매우 드문 상태 값이 아니라 정책에 대해 붓스트랩을 한다.
9.7. Case Studies
여러 케이스 스터디를 해 보자.
9.7.1. AlphaGo: Championship Level Play at Go
바둑은 2인 보드 게임이다. 체스보다 가능한 경우가 매우 많기 때문에 학습하기 어렵다. 알파고는 트리 탐색을 이용하며 트리의 최적화가 아닌 부분은 휴리스틱으로 삭제된다. 공간적 패턴은 컨볼루션 신경망으로 학습되나, 알파고는 이에 여러 특성도 추가하였다. 알파고는 반복된 게임 플레이로 인해 좋은 정책을 학습하고 추론 시간엔 몬테 카를로 트리 탐색을 한다.
Policy Networks
정책 망은 바둑판의 시각적 표현식을 입력으로 받고 상태 s에서 동작 a의 확률을 출력한다. 이는 이미 알려진 기보를 학습하는 지도학습으로 될 수도 있고 강화학습으로 될 수도 있다.
Value Networks
이 망은 컨볼루션 신경망이기도 하다.
Monte Carlo Tree Search
이후 몬테 카를로 트리 탐색이 추론 시점에 사용된다.
9.7.1.1. Alpha Zero: Enhancements to Zero Human Knowledge
이후에 나온 알파 제로는 인간 대국자의 수의 필요를 없앴다. 알파 제로는 신경망을 예측값을 실측값으로 붓스트래핑하고 실측 상태값은 몬테 카를로 시뮬레이션으로 생성된다. 알파 제로는 체스, 쇼기 등에서 압도적 기량을 냈다.
Comments on Performance
알파고는 컴퓨터와 사람 상대로 압도적인 성능을 냈다. 특히 승리를 거둔 방식이 전통적이지 않았다는 점에서 눈여겨볼만 하다. 알파 제로의 체스에서의 성과도 매우 비슷했다.
9.7.2. Self-Learning Robots
자가 학습 로봇은 인공 지능에서 매우 중요한 선두주자이다. 이는 강화 학습에 매우 잘 맞춰져 있다.
9.7.2.1. Deep Learning of Locomotion Skills
심층 학습을 통해 로봇 움직임을 학습할 수 있다. 이는 결합 토크로 인해 제어되었다. 이후 피드포워드 망이 일반화된 이득 추정자가 신뢰 기반 정책 최적화와 함께 사용되었다.
9.7.2.2. Deep Learning of Visuomotor Skills
강화 학습의 두 번째 흥미로은 경우는 시각 운동성이다. 자연스러운 기법은 컨볼루션 신경망을 이용해 이미지 프레임을 정책으로 매핑하는 것이다. 이 때 가이드된 정책 탐색 방법이 사용된다.
9.7.3. Building Conversational Systems: Deep Learning for Chatbots
챗봇은 대화 시스템이나 대화창 시스템으로도 불린다. 페이스북의 챗봇 시스템을 알아보자. 이 때 아이템의 가치는 항상 음이 아닌 것으로 가정되고 무작위로 생성된다. 이 강화 학습 세팅의 보상 함수는 사용자에게서 얻어진 가치이다. 지도 학습을 위해 대화창들은 아마존에서 학습되었다. 4개의 게이트 순환 유닛을 사용하였다. 강화 학습에 대해서는 대화창 롤아웃이 사용되었다. 마지막 예측에서는 샘플링을 통해 후보가 선택되고 이들 중 최대 확률을 내는 후보를 찾는 2단계 방법이 도입되었다. 지도학습 법은 강화 학습 법보다 성능이 좋지 못했다.
9.7.4. Self-Driving Cars
자율 주행 차는 사고나 바람직하지 못한 사건을 일으키지 않으면 보상을 받는다. 운전은 모든 상황마다 동작의 규칙을 특정하기 어렵기 때문에 매우 어렵다. 학습 데이터는 폭넓은 도로와 조건에서 모아졌다. 다른 조건은 강화 학습과 비슷하다. 이는 컨볼루션 신경망을 사용하였다. 결과는 시뮬레이션과 실제 도로에서 테스트되었다.
9.7.5. Inferring Neural Architectures with Reinforcement Learning
강화 학습의 흥미로운 적용례는 신경망 구조를 학습하는 것이다. 강화 학습은 순환 신경망을 써서 컨볼루션 신경망의 매개변수를 결정한다. 이 때 검증 집합에서의 망의 성능을 이용해 보상을 계산한다. 핵심은 자식 망의 층의 수를 결정하는 것이다.
9.8. Practical Challenges Associated with Safety
강화 학습의 복잡한 학습 알고리즘의 설계를 단순화하는 것은 예상치 못한 결과를 가져온다. 또한, 시스템이 가상 보상을 부도덕적한 방법으로 얻으려 시도할 수도 있다. 또한 새 상황에서 경험을 일반화하는 것도 어렵다.
9.9. Summary
이 장에서는 에이전트가 환경과 보상 기반 방식으로 최적의 동작을 학습하는 강화 학습 문제를 알아보았다. 강화 학습 방법에는 여러 종류가 있으며 Q-학습 방법, 정책 기반 방법이 가장 흔하다. 정책 기반 방법은 최근에 매우 유명해졌다. 이들 중 많은 방법은 심층 신경망을 감각적 입력을 받아 보상을 최적화하는 정책을 학습하는 양극 시스템이다. 강화 학습 알고리즘은 비디오나 다른 게임을 플레이하거나, 로봇, 자율 주행 차 등 많은 세팅에서 쓰인다. 이 알고리즘의 능력은 실험을 통해 학습되며 종종 다른 학습 기법으로는 불가능했던 혁신적인 해법을 낳는다. 강화 학습 알고리즘은 안전성과 관련된 특수한 난관을 갖는데 이는 보상 함수와 학습 과정의 과단순화 때문이다.
9.10. Bibliographic Notes
여러 문헌이 존재한다.
9.10.1. Software Resources and Testbeds
일부 소프트웨어가 존재한다.
